Blog posts
RDO Community Day @ FOSDEM - Schedule announced
The schedule for RDO Community Day at FOSDEM is now available at https://www.rdoproject.org/events/rdo-day-fosdem-2016/. Exact times are not confirmed, but we should have those in the next few days.
The RDO Community day is colocated with the CentOS Dojo, which should also be announcing their schedule in the coming week, featuring a Sysadmin track and a Developer track.
Lunch is provided.
Although attendance is free, you must register at Eventbright both so that we know how many lunches we need to provide, and also to ensure that the door guards will grant you entrance to the facility when you arrive.
We are excited about this event, and look forward to seeing you there.
RDO blog roundup, week of December 14
Here’s what RDO enthusiasts were blogging about last week.
Asking Me Questions about Keystone, by Adam Young
As many of you have found out, I am relatively willing to help people out with Keystone related questions. Here are a couple guidelines.
… read more at http://tm3.org/47
Setting up a local caching proxy for Fedora YUM repositories, by Daniel Berrange
For my day-to-day development work I currently have four separate physical servers, one old x86_64 server for file storage, two new x86_64 servers and one new aarch64 server. Even with a fast fibre internet connection, downloading the never ending stream of Fedora RPM updates takes non-negligible time. I also have cause to install distro chroots on a reasonably frequent basis for testing various things related to containers & virtualization, which involves yet more RPM downloads. So I decided it was time to investigate the setup of a local caching proxy for Fedora YUM repositories. I could have figured this out myself, but I fortunately knew that Matthew Booth had already setup exactly the kind of system I wanted, and he shared the necessary config steps that are outlined below.
… read more at http://tm3.org/48
Why cloud-native depends on modernization by Gordon Haff
This is the fourth in a series of posts that delves deeper into the questions that IDC’s Mary Johnston Turner and Gary Chen considered in a recent IDC Analyst Connection. The fourth question asked: What about existing conventional applications and infrastructure? Is it worth the time and effort to continue to modernize and upgrade conventional systems?
… read more at http://tm3.org/49
HA for Tripleo, by Adam Young
Juan Antonio Osorio Robles was instrumental in me getting Tripelo up and running. He sent me the following response, which he’s graciously allowed me to share with you.
… read more at http://tm3.org/4a
New Neutron testing guidelines!, by Addaf Muller
Yesterday we merged https://review.openstack.org/#/c/245984/ which adds content to the Neutron testing guidelines:
… read more at http://tm3.org/4b
Rippowam, by Adam Young
Ossipee started off as OS-IPA. As it morphed into a tool for building development clusters,I realized it was more useful to split the building of the cluster from the Install and configuration of the application on that cluster. To install IPA and OpenStack, and integrate them together, we now use an ansible-playbook called Rippowam.
… read more at http://tm3.org/4c
**In-use Volume Backups in Cinder ** by Gorka Eguileor
Prior to the Liberty release of OpenStack, Cinder backup functionality was limited to available volumes; but in the latest L release, the possibility to create backups of in-use volumes was added, so let’s have a look into how this is done inside Cinder.
… read more at http://tm3.org/4d
RDO blog roundup, week of December 8
After a really quiet week last week, we have a lot of great blog posts this week.
Our cloud in Kilo, by Tim Bell
Following on from previous upgrades, CERN migrated the OpenStack cloud to Kilo during September to November. Along with the bug fixes, we are planning on exploiting the significant number of new features, especially as related to performance tuning. The overall cloud architecture was covered at the Tokyo OpenStack summit video https://www.openstack.org/summit/tokyo-2015/videos/presentation/unveiling-cern-cloud-architecture.
… read more at http://tm3.org/41
Evolving IT architectures: It can be hard, by Gordon Haff
This is the second in a series of posts that delves deeper into the questions that IDC’s Mary Johnston Turner and Gary Chen considered in a recent IDC Analyst Connection. The second question asked: What are the typical challenges that organizations need to address as part of this evolution [to IT that at least includes a strong cloud-native component]?
… read more at http://tm3.org/42
How cloud-native needs cultural change, by Gordon Haff
This is the third in a series of posts that delves deeper into the questions that IDC’s Mary Johnston Turner and Gary Chen considered in a recent IDC Analyst Connection. The third question asked: How will IT management skills, tools, and processes need to change [with the introduction of cloud-native architectures]?
… read more at http://tm3.org/43
Getting Started with Tripleo by Adam Young
OpenStack is big. I’ve been focused on my little corner of it, Keystone, for a long time. Now, it is time for me to help out with some of the more downstream aspects of configuring RDO deployments. In order to do so, I need to do an RDO deployment. Until recently, this has meant Packstack. However, Packstack really is not meant for production deployments. RDO manager is the right tool for that. So, I am gearing up on RDO manager. The upstream of RDO Manager is TripleO.
… read more at http://tm3.org/44
Testing OpenStack is hard by David Moreau Simard
Testing OpenStack is hard There is currently almost 50 official OpenStack projects There is over 1000 source and binary packages built and provided by the official RDO repositories These packages are bundled, integrated or provided by many different installers and vendors There are countless deployment use cases ranging from simple private clouds to large scale complex and highly available public clouds
… read more at http://tm3.org/45
Thinking outside the box and outside the gate to improve OpenStack and RDO by David Moreau Simard
I recently explained how testing everything in OpenStack is hard. The reality is that the RDO community has finite resources. Testing everything is not just hard, it’s time consuming and expensive. I’ve been thinking a lot about how to tackle this and experimented around ways to improve our test coverage in this context.
… read more at http://tm3.org/46
RDO blog roundup, week of November 23
Here’s what RDO engineers have been blogging about lately:
Automated API testing workflow by Tristan Cacqueray
Services exposed to a network of any sort are in risk of security exploits. The API is the primary target of such attacks, and it is often abused by input that developers did not anticipate.
… read more at http://tm3.org/3y
RDO Community Day @ FOSDEM by Rich Bowen
We’re pleased to announce that we’ll be holding an RDO Community Day in conjunction with the CentOS Dojo on the day before FOSDEM. This event will be held at the IBM Client Center in Brussels, Belgium, on Friday, January 29th, 2016.
… read more at http://tm3.org/3z
Translating Between RDO/RHOS and Upstream OpenStack releases by Adam Young
There is a straight forward mapping between the version numbers used for RDO and Red Hat Enterprise Linux OpenStack Platform release numbers, and the upstream releases of OpenStack. I can never keep them straight. So, I write code.
… read more at http://tm3.org/3-
Does cloud-native have to mean all-in? by Gordon Haff
Cloud-native application architectures promise improved business agility and the ability to innovate more rapidly than ever before. However, many existing conventional applications will provide important business value for many years. Does an organization have to commit 100% to one architecture versus another to realize true business benefits?
… read more at http://tm3.org/40
RDO Community Day @ FOSDEM
The schedule has now been published at https://www.rdoproject.org/events/rdo-day-fosdem-2016/.
We’re pleased to announce that we’ll be holding an RDO Community Day in conjunction with the CentOS Dojo on the day before FOSDEM. This event will be held at the IBM Client Center in Brussels, Belgium, on Friday, January 29th, 2016.
You are encouraged to send your proposed topics and sessions via the Google form. If you have questions about the event, or proposed topics, bring them either to the rdo-list mailing list, or to the #rdo channel on the Freenode IRC network.
If you’re thinking of attending either the RDO Day, or the CentOS Dojo, please register so that we know how many people to expect.
Automated API testing workflow
Services exposed to a network of any sort are in risk of security exploits. The API is the primary target of such attacks, and it is often abused by input that developers did not anticipate.
This article introduces security testing of Openstack services using fuzzing techniques
This article will demonstrate how OpenStack services could be automatically tested for security defects. First, I will introduce a set of tools called RestFuzz to demonstrate how it works in practice. Second, I will discuss the limitations of RestFuzz and how more advanced techniques could be used.
The end goal is to design an automatic test to prevent a wide range of security bugs to enter OpenStack’s source code.
How a fuzzer works
A fuzzer’s purpose is to discover issues like OSSA 2015-012 by injecting random inputs into the target program. This advisory shows how a single invalid input, accepted by the API, broke the entire L2 network service. While code review and functional tests are not good at spoting such mistake, a fuzz test is a proven strategies to detect security issues.
A fuzzer requires at least two steps: first, inputs need to be generated and fed to the service’s input; and second, errors needs to be detected.
OpenStack API description
To reach the actual service code, a fuzzer will need to go through the REST interface routing, which is based on HTTP method and url. One way to effectively hit the interesting parts of the service code is to replay known valid HTTP queries. For example, a fuzzer could re-use HTTP requests created by tempest functional tests. However, this method is limited by its trace quality. Instead, RestFuzz works the other way around and generates valid queries based on API definitions. That way, it covers actions that functional tests do not use, such as unusual combinaisons of parameters.
To keep the process simple, RestFuzz will need a description of the API that defines the methods’ endpoint and inputs’ types. While in theory the API description could be generated dynamically, it’s easier to write it down by hand.
As a C function description, a REST API method description could be written in YAML format like this:
- name: 'network_create'
url: ['POST', 'v2.0/networks.json']
inputs:
network:
name: {'required': 'True', 'type': 'string'}
admin_state_up: {'type': 'bool'}
outputs:
network_id: {'type': 'resource', 'json_extract': 'lambda x: x["network"]["id"]'}
This example from the network api defines a method called “network_create” using:
- The HTTP method and url to access the API.
- The description of the method’s parameters’ name and types.
- The description of the expected outputs along with a lambda gadget to ease value extraction from JSON output.
The method object shows how to call network_create based on the above description. Note that the call procedure takes a dictionary as JSON inputs. The next chapter will cover how to generate such inputs dynamically.
Input generation
An input constructor needs to be implemented for each type. The goal is to generate data known to cause application errors.
The input_generator object shows the api call parameters can be dynamically generated by using the method input description shown above. Here are a couple of input generators:
def gen_string():
chunk = open("/dev/urandom").read(random.randint(0, 512))
return unicode(chunk, errors='ignore')
def gen_address_pair():
return {
"ip_address": generate_input("cidr"),
"mac_address": generate_input("mac_address")
}
Note that “resource” types are UUID data, which can’t be randomly generated. Thus, the fuzzer needs to keep track of method outputs to reuse valid UUID whenever possible.
The fuzzer can now call API methods with random inputs, but, it still needs to monitor service API behavior. This leads us to the second steps of error detection.
OpenStack error detection
This chapter covers a few error detection mechanisms that can be used with OpenStack components.
HTTP Error code
OpenStack services’ API will return theses important error codes:
- 401 tells the keystone token needs to be refreshed
- 404 tells a UUID is no longer valid
- 500 tells unexpected error
Tracebacks in logs
Finding tracebacks in logs is usually a good indicator that something went wrong. Moreover, using file names and line numbers, a traceback identifier could be computed to detect new unique errors. The health object features a collect_traceback function.
API service process usage
Finaly cgroups can be used to monitor API services memory and CPU usage. High CPU loads or constant growth of reserved memory are also good indicators that something went wrong. However this requires some mathematical calculations which are yet to be implemented.
Fuzzing Workflow
All together, a fuzzing process boils down to:
- choose a random method
- call method using random inputs
- probe for defect
- repeat
The ApiRandomCaller object uses random.shuffle to search for random methods and returns an Event object to the main process starting here.
RestFuzz features
Console output:
$ restfuzz --api ./api/network.yaml --health ./tools/health_neutron.py
[2015-10-30 06:19:09.685] port_create: 201| curl -X POST http://127.0.0.1:9696/v2.0/ports.json -d '{"port": {"network_id": "652b1dfa-9bcb-442c-9088-ad1a821020c8", "name": "jav
ascript:alert('XSS');"}}' -> '{"port": {"id": 2fc01817-9ec4-43f2-a730-d76b70aa4ea5"}}'
[2015-10-30 06:19:09.844] security_group_rule_create: 400| curl -X POST http://127.0.0.1:9696/v2.0/security-group-rules.json -d '{"security_group_rule": {"direction": "ingress", "port_range_max": 9741, "security_group_id": "da06e93b-87a3-4d90-877b-047ab694addb"}}' -> '{"NeutronError": {"message": "Must also specifiy protocol if port range is given.", "type": "SecurityGroupProtocolRequiredWithPorts", "detail": ""}}'
[2015-10-30 06:19:10.123] security_group_create: 500| curl -X POST http://127.0.0.1:9696/v2.0/security-groups.json -d '{"security_group": {"name": ["Dnwpdv7neAdvhMUcqVyQzlUXpyWyLz6cW2NPPyA6E8Z9FbvO9mVn1hs30rlabVjtVHy6yCQqpEp0xcF1AsWZYAPThstCZYebxKcJaiS7o7fS0GsvG3i8kQwNzOl5F1SiXBxcmywqI9Y6t0ZuarZI787gzDUPpPY0wKZL69Neb87mZxObhzx4sgWHIRGfsrtYTawd6dYXYSeajEDowcr1orVwJ6vY"]}}' -> '{"NeutronError": {"message": "Request Failed: internal server error while processing your request.", "type": "HTTPInternalServerError", "detail": ""}}', /var/log/neutron/q-svc.log
File "/opt/stack/neutron/neutron/api/v2/resource.py", line 83, in resource
result = method(request=request, **args)
File "/opt/stack/neutron/neutron/api/v2/base.py", line 391, in create
allow_bulk=self._allow_bulk)
File "/opt/stack/neutron/neutron/api/v2/base.py", line 652, in prepare_request_body
attr_vals['validate'][rule])
File "/opt/stack/neutron/neutron/extensions/securitygroup.py", line 195, in _validate_name_not_default
...
Network topology after one hour of fuzz test:
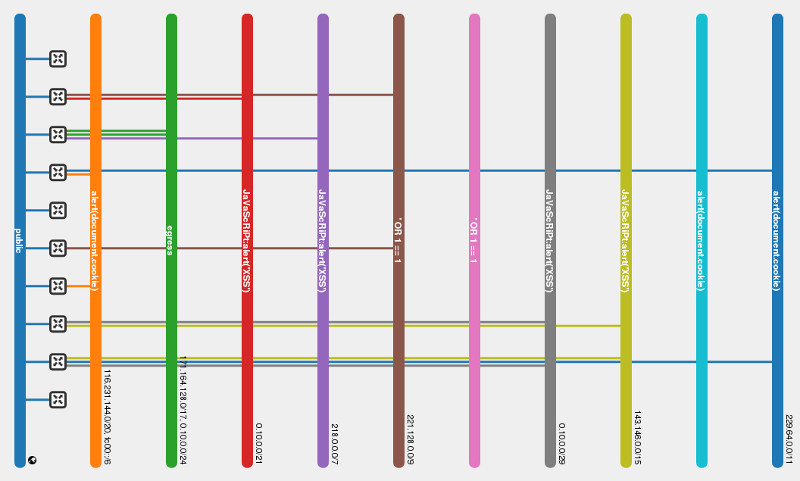
Interesting features:
- API description works for block storage (Cinder), image (Glance), network (Neutron) and dns (Designate).
- Input generator randomly inter-changes types using a “chaos monkey” behavior to abuse the API even more.
- Health plugin implements custom probe per services.
- Simple workflow where methods are called in random order. An early version tried to build a graph to walk through the API more efficiently, but it turns out that calling method randomly is efficient enough and it keeps the code much more simple. See this image for a dependency graph of the network API.
- More importantly, it already found a bunch of security defect like bug #1486565 or bug #1471957. The full list is available in the README.
{kind=link}
However, RestFuzz is a proof of concept and it’s not ready to be used as an efficient gate mechanism. The next part of this article discusses the limitations reached and what needs to be done to get something awesome!
Limitations and improvments
It’s built from the ground up
RestFuzz currently only requires python-requests and PyYAML. A good chunk of the code could use frameworks such as the syntribos and/or gabbi
API description
Managing API descriptions is a great limitation, as the fuzzer will only be as good as the API description. OpenStack really needs to provide us the API description in a unified and consistent format:
- API Documentation does not describe the input object precisely enough, making it impossible to use automatically.
- Service documentation is sporadic and REST API routing is done differently in most OpenStack projects.
- Command line tools may provide a good base, but they usualy omit unusual parameters and service extensions.
Having an unified API description will give a fuzzer bigger code coverage.
Complex types generation
A formal description of API inputs is a real challenge. Some services like Heat or Sahara can take flat files as input that would requires dedicated input generators. Otherwise, services like Designate need coherent inputs to pass early checks. E.G., the domain name used at zone creation needs to be reused for record creation.
In theory, this limitation could be mitigated using better instruments like guided fuzzing.
Guided fuzzing
A modern fuzzer like American Fuzzy Lop (afl) is able to monitor which instructions are executed by the target program and then use “rock-solid instrumentation-guided genetic algorithm” to produce inputs. In short, afl can generate valid input out of thin air without any description.
However afl is difficult to put in place for network services because it requires services’ modification. python-afl bridges the Python interpreter with the fuzzer, and it may be interesting for OpenStack services testing.
Anomalies detection probes
Better watchdog processes could be used in paralel to detect silent logic flaws. Stacktraces and 500 errors most often reveal basic programing flaws. If one of the following actions fail, it’s a good sign something is defective:
- Boot an instance, assign an ip and initiate connection
- Test methods with expected output like with gabbi
- Run functional tests
Fuzzer As A Service
A fuzzer could also be implemented as an OpenStack service that integrates nicely with the following components:
- Compute resources with Nova
- Database store with Trove
- Message bus for parallel testing with Zaquar
- Data processing with Sahara/Sparks
Conclusion
Fuzzing is a powerful strategy to pro-actively detect security issues. Similar to bandit the end goal is to have an automatic test to detect and prevent many kinds of code defect.
While RestFuzz is really just a naïve proof of concept, it nonetheless indicated important limitations such as the lack of API description. I would appreciate feedback and further would like to create an upstream community to implement OpenStack fuzz testing.
This effort could start as an offline process with automatic reporting of traceback and 500 errors. But ultimately this really needs to be used as a gating system to prevent erroneous commits to be released.
I’d like to thank fellow Red Hat engineers Gonéri Le Bouder, Michael McCune, and George Peristerakis for their support and early reviews.
RDO blog roundup, week of November 9
Here’s what RDO enthusiasts were blogging about this week. If you were at OpenStack Summit in Tokyo last month, don’t forget to write up your experience.
RDO Liberty released in CentOS Cloud SIG, by Alan Pevec
We are pleased to announce the general availability of the RDO build for OpenStack Liberty for CentOS Linux 7 x86_64, suitable for building private, public and hybrid clouds. OpenStack Liberty is the 12th release of the open source software collaboratively built by a large number of contributors around the OpenStack.org project space.
… read more at http://tm3.org/3d
Neutron HA Talk in Tokyo Summit by Assaf Muller
Florian Haas, Adam Spiers and myself presented a session in Tokyo about Neutron high availability. We talked about:
… read more at http://tm3.org/3s
OpenStack Summit Tokyo by Matthias Runge
Over the past week, I attended the OpenStack Summit in Tokyo. My primary focus was on Horizon sessions. Nevertheless, I was lucky to have one or two glimpses at more touristic spots in Tokyo.
… read more at http://tm3.org/3t
OpenStack Summit Tokyo – Final Summary by Gordon Tillmore
As I flew home from OpenStack Summit Tokyo last week, I had plenty of time to reflect on what proved to be a truly special event. OpenStack gains more and more traction and maturity with each community release and corresponding Summit, and the 11th semi-annual OpenStack Summit certainly did not disappoint. With more than 5,000 attendees, it was the largest ever OpenStack Summit outside of North America, and there were so many high quality keynotes, session, and industry announcements, I thought it made sense to put together a final trip overview, detailing all of the noteworthy news, Red Hat press releases, and more.
… read more at http://tm3.org/3u
Community Meetup at OpenStack Tokyo by Rich Bowen
A week ago in Tokyo, we held the third RDO Community Meetup at the OpenStack Summit. We had about 70 people in attendance, and some good discussion. The full agenda for the meeting is at https://etherpad.openstack.org/p/rdo-tokyo and below are some of the things that were discussed. (The complete recording is at the bottom of this post.)
… read more at http://tm3.org/3v
Mike Perez: Cinder in Liberty by Rich Bowen
Before OpenStack Summit, I interviewed Mike Perez about what’s new in Cinder in the LIberty release, and what’s coming in Mitaka. Unfortunately, life got a little busy and I didn’t get it posted before Summit. However, with Liberty still fresh, this is still very timely content.
… read more at http://tm3.org/3w
Mike Perez: Cinder in Liberty
Before OpenStack Summit, I interviewed Mike Perez about what’s new in Cinder in the LIberty release, and what’s coming in Mitaka. Unfortunately, life got a little busy and I didn’t get it posted before Summit. However, with Liberty still fresh, this is still very timely content.
In this interview, Mike talks about the awesome new features that have gone into Cinder for Liberty, and what we can expect to see in April.
If the audio player below doesn’t work for you, you can download the full audio HERE. See also the complete transcript below.
Rich: Today I’m speaking with Mike Perez, who is the PTL of the Cinder project. Cinder has been around for …
Mike: Since the Folsom release.
R: So, quite a while. Thanks for taking time to talk with me.
I wonder if you could start by giving us a real quick definition of Cinder. I know that people who are new to OpenStack are frequently a little bit confused as to what it is, and how it differs from Swift and various other storage type things that are part of OpenStack.
M: Cinder, just like a variety of other OpenStack projects, is just an API layer. So unlike other projects like Swift, for example, which is an actual implementation of a type of storage, that’s where there would be a little bit of a difference right there.
In particular, Cinder is more interested in providing block storage, as opposed to object storage. They have differences in terms of how exactly you interact with retrieving the data, as well as adding data to it, and then they also support different types of use cases. In particular, just without Cinder or Swift in the picture, if you just have your OpenStack cloud with Nova and Neutron, you just have ephemeral storage that you’re using with your instances. Typically, with those type of setups, your storage goes away as soon as the instance goes away. Adding Cinder into the picture, though, you are given the ability to have persistent storage, so that the storage itself becomes completely independent of the actual virtual machine instance. So when you terminate your virtual machine instance on the Nova side, there will be a detach of that block storage volume, and then you can later on attach it to another virtual machine instance.
R: Tell us about Liberty. What’s new in Cinder?
M: Inside of the Liberty release we have 16 new volume drivers. They’re all backed with Cinder continuous integration testing that we adopt from Tempest. Cinder has one of the most - I would say - the most drivers out of the OpenStack projects. We’re just shy of around 60 volume drivers now. Some of them are from multiple vendors. As I mentioned before, they are all backed behind the continuous integration, so we know for a fact, as we are going through a development cycle in Liberty, these volume drivers, the actual back-ends themselves, are being tested. Every single vendor is expected to have a CI system in their own lab, hooked up to a real storage solution that they are trying to support inside of Cinder. That patch will bring us - they’re expected for their CI to bring up a CI instance that connects to that storage back-end and runs their Tempest tests, and verify that that patch doesn’t break their integration with their volume driver. That came back in the Kilo release. The story’s in a lot of different places. It was a lot of fun getting us to that point. It’s been nice talking to other projects, because I know a lot of other projects are interested in going down the same path, and it’s been great having discussions with a variety of other PTLs on it.
And along with that we added in support for image caching. You have an image inside of Glance that you want to boot up a VM with that image. And with Cinder in particular, since the storage itself is in some other remote location from that virtual machine, because we’re attaching over something like ISCSI or fibrechannel, grabbing the image from wherever Glance is at, whatever Glance store is set up with Glance itself - could be inside of Swift for example, you have an image inside of Swift - and you want to put that image onto a newly allocated space volume inside of Cinder, in order to do that, it has to go across the network to whatever storage solution Cinder is set up with, and that can be really time consuming, especially for some of our users that are using 20-40Gb images. It can take a lot of time to boot up that VM. Cinder itself has a very generic image caching solution that we added in for the Liberty release, that allows for the most popular images inside of your cloud to be cached within the back-end storage solution. So what that means is, for that cache we can do some really smart things with the different storage solution. Instead of doing copy of the actual image, we can do copy-on-writes, for example. So it’s pretty much a zero copy, you’re just pointing a reference to that image that’s already allocated on that storage solution. And then create a new volume off of that reference pointer. Bam! You have a new volume that is set up with that image, and there’s zero copies that had to happen. I think that’s going to take care of a really popular problem, that comes up, and should make users really happy for this release.
Some of the other things that we added support for that are kind of general things is nested quota support, for example. Keystone has this ability with having projects within projects. Users and operators want to be able to have the ability to set quotas based on having a hierarchy for quotas. I’m not sure about other projects, but Cinder has added this in now for the Liberty release, so you will be able to add that with your different volume allocation, as well as your gigabyte allocation as well, for project hierarchy.
The third piece I would add in is the non-disruptive backups. Cinder has this ability for doing backups. These are different from snapshots. Snapshots, you’re typically doing the actual volume itself. You’re copying the entire allocation of that volume. So, let’s say you have a 100G volume, and you’re only using 5G of it, it’s still doing a snapshot of 100G, even unused parts. The difference with a backup is you have the ability to do a backup of just the contents, what you’re actually using. And on top of it you’re also able to have the volume backed up to another location, let’s say you could set up a Cinder backup service that is able to talk to Swift. For your Cinder side, you have Ceph set up. So you have completely two separate storage solutions, and if something were to happen to the Ceph storage solution, everything would still be backed up on this other Swift cluster that’s completely independent.
The problem with doing backups, though, typically was - and this is just with block storage in general - is you would have to detach the volume from it being used by the VM, and then you would have to initiate a backup, and then reattach that volume to the Cinder backup solution which would then go ahead and put it into the Swift cluster. That could be disruptive. The new solution that now we have is, some of the different back-end solutions that we’re using for the Cinder backups will give you the ability to keep the volume attached, and actively being used, but we can go ahead and initiate a backup, and it will keep copying over the bits, and hopefully eventually catch up to where the volume is at, to a point where it can stop the backups, and your volume can continue being used in production.
I would say those are the most interesting for the Liberty release.
R: What’s your vision, looking forward, for Mitaka and on, for Cinder.
M: I sort of talked about this in the previous Liberty release, and unfortunately we weren’t exactly able to finish everything up in time. My apologies to everyone. But for the operator side, we have been working on trying to make rolling upgrades a real thing, instead of just talking about it. Initially, for the Kilo release, we worked on a solution inside of Oslo that gives you the ability to have the OpenStack services themselves be written in a way to be independent from the actual database solution that’s being used. Typically when you do upgrade you have to bring down - whatever services you’re going to upgrade, you have bring down those services, and then you have to do a database upgrade. And for real OpenStack users, that can be very time consuming because of all the different column changes that have to happen for all of the different rows of data that they have. During that time, you have down time of those services. So, for the Kilo release we ended up working on a solution that made those services where they could continue running, and you could run the database upgrade and there would be no disruption. And when you found it convenient to do it, you can restart those services so that they could take advantage of the new database changes. But they could continue to run even with the database changes happening underneath. So that was added in Oslo, and we made that available for all OpenStack projects, not just Cinder, to take advantage of.
What we’re working on for the M release, and what we were working on for Liberty as well, is the ability to have the services be independent of each other. The way that they communicate with each other is with RPC. For example, if you have, in the Cinder case, typical setup is you have a Cinder API server, you have a Cinder scheduler, and you have a Cinder volume manager. And as soon as you upgrade one of those services, they can no longer talk to each other. So, having the ability, as an operator, to roll out the updates to, say, all of my Cinder APIs, and verify that everything looks good, and then to make the decision, ok, now I want to update the Cinder scheduler. So it’s all about being comfortable, and having things be convenient for the operator. So the RPC compatibility layer will allow the operator to do those upgrades at their own pace.
And, just like what we did with the Cinder database upgrade case, we’re trying to make this a generic solution so that we can allow all OpenStack projects to take advantage of this same solution.
Very likely, just like what we did before, it will be something that will surface up into the Oslo library as well.
One feature that I know in particular that will be coming out, that has already finished in the Liberty release, but we just didn’t have any of our volume drivers take advantage of it yet, is just some basic replication ability. To be able to say that I have this volume, which is the primary, and have other volumes that for that particular volume will be replicated over. And if anything was to happen to the primary volume, it would fail over to the secondary volume. So, really basic replication, and we’re not trying to do all the bells and whistles out of the box right now, so it is a manual failover case. From what we’ve got in previous summit discussions, people were kind of OK anyways with doing manual failover. Weren’t completely comfortable with trusting software to do auto-failover. Eventually we’ll get over there, but I think getting all volume drivers over to supporting replication is a big win.
And then for the rest of the M release, I would say is a lot of catchup with some of the other projects in terms of the ability - this is not really something for the users, or the actual operators themselves - but the support of microversions. Just having the ability for us to progress forward in the API while still preserving some backward compatibility.
And then, the last part that I would say that may still not be
something noticeable to users and operators, but we are working a lot
more closely with the Nova team. In previous times there hasn’t been a
lot of interactions between the two teams, and Nova uses the Cinder
API pretty heavily in the cases where persistent storage is needed.
And I would say that currently, today, we have quite a number of
issues that we’re trying to work through in terms of how they’re
expecting to use our API, and how well we defined our API to them
initially. So, I wouldn’t really say it’s a fault in anybody that’s
been using our API, but more us trying to figure out how to define to
people that want to use our API how it should be used properly.
And now we’re trying to clean that up as we go.
So, basically, we should see in the M release is better interaction between Nova and Cinder and, if there are any issues that happen in those interactions, that they’ll be able to recover from those issues. So any time that Nova wants to create a volume and attach it, and something were fail in between there, there would be some sort of recovery that would happen, that the user can understand what just happened, and could take action from there. Because currently, today, there’s really not much information for the user to go by to know what to do next.
R: Thank you very much for taking the time to do this.
M: No problem.
Community Meetup at OpenStack Tokyo
A week ago in Tokyo, we held the third RDO Community Meetup at the OpenStack Summit. We had about 70 people in attendance, and some good discussion. The full agenda for the meeting is at https://etherpad.openstack.org/p/rdo-tokyo and below are some of the things that were discussed. (The complete recording is at the bottom of this post.)
People who were in attendance, please feel free to update and annote your section of this report if you wish to add detail, or if I get anything wrong.
We started with a discussion of how the project is governed. It was observed that although we have a weekly meeting, it’s not always possible for everyone to attend, but that these meetings are summarized back to the mailing list each week.
We announced that the new RDO website is live (you’re looking at it now!) and that it is possible to send pull requests for it now.
Haikel asked whether there was any interest in his project of an RDO aarch64 port, and identified a few people who expressed interest.
Trown talked a bit about the status of RDO-Manager in Liberty. Liberty is the first release where RDO-Manager has released at the same time, which is a big step. He briefly discussed the RDO Manager quickstart that is being worked on. Check back here later for a link to Trown’s more detailed writeup.
Regarding the question of the relationship between RDO Manager and TripleO, it was established that RDO Manager is a downstream of TripleO, rather than being an upstream effort. It’s more than just TripleO, but, rather, is a distribution of several tools, built on top of TripleO.
We spoke briefly about documenting what all of the moving pieces of the RDO project are, and how they fit together. Haikel said that he’s made a start at documenting this, and drawing diagrams. He also encourage people to step up to participate in both documenting, and in improving the infrastructure.
A discussion arose about what the process is to get an upstream patch into RDO. From this, an action item was raised to more clearly document what the process is to request patches, and where to file tickets.
We discussed the timing and frequency of test days in the Mitaka cycle, and this was later discussed more on IRC. The consensus was that there should be a test day about a week after each milestone, with a sanity check done during that week so that we don’t have a catastrophic test day. Now that the Mitaka release schedule is published we should be able to put together a tentative test day schedule very soon.
An overview was given of the RPM packaging effort in upstream OpenStack.
The relationship with CentOS was discussed, in particular the manual process required to push packages up to the repos. This process still requires that we ping the CentOS admins, but this will soon be an automated process. Haikel also enumerated the various reasons that the relationship with CentOS is still of great benefit to RDO, including exposure to a wider audience due to CentOS’s recognized name. There was also a view expressed that we should run an RDO-based cloud, perhaps in addition to the CentOS infrastructure, so that we are testing on our own platform.
Finally, Rich Megginson spoke about the data aggregation effort that he is working on with Tushar Katarki. Rich has written a more detailed writeup of that section.
Finally, a quick announcement was made of the upcoming RDO Community Day at FOSDEM.
If you’d like to hear more detail from the meetup, I’ve put the complete recording up, and you can listen below. (59 minutes, 109 MB)
RDO blog roundup, week of November 3
Due to travels, it’s been 2 weeks since the last RDO blog update. In conjuction with OpenStack Summit having been last week, this means that I have a huge list of blog posts to catch you up on this week.
Ansible 2.0: The Docker connection driver, by Lars Kellogg-Stedman
As the release of Ansible 2.0 draws closer, I’d like to take a look at some of the new features that are coming down the pipe. In this post, we’ll look at the docker connection driver.
… read more at http://tm3.org/35
RDO test day summary by Rich Bowen
A big thanks to everyone that participated in the RDO Test Day over the last 48 hours. Here’s a few statistics from the day.
… read more at http://tm3.org/36
Bootstrapping Ansible on Fedora 23 by Lars Kellogg-Stedman
If you’ve tried running Ansible against a Fedora 23 system, you may have run into the following problem:
… read more at http://tm3.org/37
Stupid Ansible Tricks: Running a role from the command line by Lars Kellogg-Stedman
When writing Ansible roles I occasionally want a way to just run a role from the command line, without having to muck about with a playbook. I’ve seen similar requests on the mailing lists and on irc.
… read more at http://tm3.org/38
Admin, by Adam Young
While I tend to play up bug 968696 for dramatic effect, the reality is we have a logical contradiction on what we mean by ‘admin’ when talking about RBAC.
… read more at http://tm3.org/39
Announcing the Release of Kolla Liberty by Steve Dake
Hello OpenStackers! The Kolla community is pleased to announce the release of the Kolla Liberty. This release fixes 432 bugs and implements 58 blueprints!
… read more at http://tm3.org/3a
DevOps in a Bi-Modal World (Part 3 of 4) by James Labocki
In Part 2 of this series, we discussed what IT needs to do in a Mode 1 world to make itself more relevant to the business and reduce complexity. In this part, we will turn our attention to Mode 2 and discuss how the organization can solve its challenges by improving agility and increasing scalability.
… read more at http://tm3.org/3b
Cinder HA Active-Active specs up for review by Gorka Eguileor
It’s been some time since the last time I talked here about High Availability Active-Active configurations in Openstack’s Cinder service, and now I am quite pleased -and a little bit embarrassed it took so long- to announce that all specs are now up for reviewing.
… read more at http://tm3.org/3c
RDO Liberty released in CentOS Cloud SIG by Alan Pevec
We are pleased to announce the general availability of the RDO build for OpenStack Liberty for CentOS Linux 7 x86_64, suitable for building private, public and hybrid clouds. OpenStack Liberty is the 12th release of the open source software collaboratively built by a large number of contributors around the OpenStack.org project space.
… read more at http://tm3.org/3d
DevOps in a Bi-Modal World (Part 4 of 4) by James Labocki
In this series we have seen the complexity of bridging the gap between existing infrastructure and processes (Mode 1) and new, agile processes and architectures (Mode 2). Each brings its own set of challenges and demands on the organization. In Mode-1 organizations are looking to increase relevance and reduce complexity, and in Mode-2 they are looking to improve agility and increase scalability. In this post we will discuss how Red Hat addresses and solves each of these challenges.
… read more at http://tm3.org/3e
OpenStack Security Groups using OVN ACLs by Russell Bryant
OpenStack Security Groups give you a way to define packet filtering policy that is implemented by the cloud infrastructure. OVN and its OpenStack Neutron integration now includes support for security groups and this post discusses how it works.
… read more at http://tm3.org/3f
RDO Liberty DVR Neutron workflow on CentOS 7.1 by Boris Derzhavets
Per http://specs.openstack.org/openstack/neutron-specs/specs/juno/neutron-ovs-dvr.html DVR is supposed to address following problems which has traditional 3 Node deployment schema:-
… read more at http://tm3.org/34
Why the Operating System Matters by Margaret Dawson
In IT today, we love to note that the infrastructure layer has become commoditized. This started with virtualization, as we could create many virtual machines within a single physical machine. Cloud has taken us further with a key value proposition of delivering cloud services on any standard server or virtualized environment, enabling easier scalability and faster service delivery, among other benefits.
… read more at http://tm3.org/3g
Ansible 2.0: New OpenStack modules by Lars Kellogg-Stedman
This is the second in a loose sequence of articles looking at new features in Ansible 2.0. In the previous article I looked at the Docker connection driver. In this article, I would like to provide an overview of the new-and-much-improved suite of modules for interacting with an OpenStack environment, and provide a few examples of their use.
… read more at http://tm3.org/3h
OpenStack Summit Tokyo – Day 0 (Pre-event) by Jeff Jameson
I’ve always enjoyed traveling to Tokyo, Japan, as the people are always so friendly and willing to help. Whether it’s finding my way through the Narita airport or just trying to find a place to eat, they’re always willing to help – even with the language barrier. And each time I visit, I see something new, learn another word (or two) in Japanese, and it all just seems new and exciting all over again. Add in the excitement and buzz of an OpenStack Summit and you’ve got a great week in Tokyo!
… read more at http://tm3.org/3i
Ducks by Rich Bowen
Why ducks?
… read more at http://tm3.org/3j
A Container Stack for OpenStack (Part 1 of 2) by Joe Fernandes
Open source continues to be a tremendous source of innovation and nowhere is that more evident than at the biannual OpenStack Summit. Over the past couple of years, as OpenStack interest and adoption has grown, we’ve seen another important innovation emerge from the open source community in the form of Linux containers, driven by Docker and associated open source projects. As the world gathers in Tokyo for another OpenStack Summit, we wanted to talk about how Red Hat is bringing these two innovations together, to make OpenStack a great platform for running containerized applications.
… read more at http://tm3.org/3k
OpenStack Summit Tokyo – Day 1 by Jeff Jameson
Kon’nichiwa from Tokyo, Japan where the 11th semi-annual OpenStack Summit is officially underway! This event has come a long way from its first gathering, more than five years ago, where 75 people gathered in Austin, Texas to learn about OpenStack in its infancy. That’s a sharp contrast with the 5,000+ people in attendance here in what marks Asia’s second OpenStack Summit.
… read more at http://tm3.org/3l
What does RDO stand for? by Rich Bowen
The RDO FAQ has long said that RDO doesn’t stand for anything. This is a very unsatisfying answer to one of the most frequently asked questions about RDO. So, a little while ago, I started saying that RDO stands for “Rich’s Distribution of OpenStack.” Although tongue-in-cheek, this response emphasizes that RDO is a community driven project. So it’s also Radez’s Distribution of OpenStack, and Radhesh’s and Russel’s and red_trela’s. (As well as lots of people whose names don’t start with R!)
… read more at http://tm3.org/3m
Proven OpenStack solutions. Simple OpenStack deployment. Powerful results. by Radhesh Balakrishnan
According to an IDC global survey sponsored by Cisco of 3,643 enterprise executives responsible for IT decisions, 69% of respondents indicated that their organizations have a cloud adoption strategy in place. Of these organizations, 65% say OpenStack is an important part of their cloud strategy and had higher expectations for business improvements associated with cloud adoption.
… read more at http://tm3.org/3n
OpenStack Summit Tokyo – Day 2 by Jeff Jameson
Hello again from Tokyo, Japan where the second day of OpenStack Summit has come to a close with plenty of news, interesting sessions, great discussion on the showfloor, and more.
… read more at http://tm3.org/3o
A Container Stack for OpenStack (Part 2 of 2) Joe Fernandes
In Part 1 of this blog series, I talked about how Red Hat has been working with the open source community to build a new container stack and our commitment to bring that to OpenStack. In Part 2 I will discuss additional capabilities Red Hat is working on to build an enterprise container infrastructure and how this is forms the foundation of our containerized application platform in OpenShift.
… read more at http://tm3.org/3p
OpenStack Summit Tokyo – Day 3 by Jeff Jameson
Hello again from Tokyo, Japan where the third and final day of OpenStack Summit has come to a close. As with the previous days of the event, there was plenty of news, interesting sessions, great discussions on the show floor, and more. All would likely agree that the 11th OpenStack Summit was a rousing overall success!
… read more at http://tm3.org/3q
Puppet OpenStack plans for Mitaka by Emilien Macchi
Our Tokyo week just ended and I really enjoyed to be at the Summit with the Puppet OpenStack folks. This blog post summarizes what we did this week and what we plan for the next release.
… read more at http://tm3.org/3r